Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
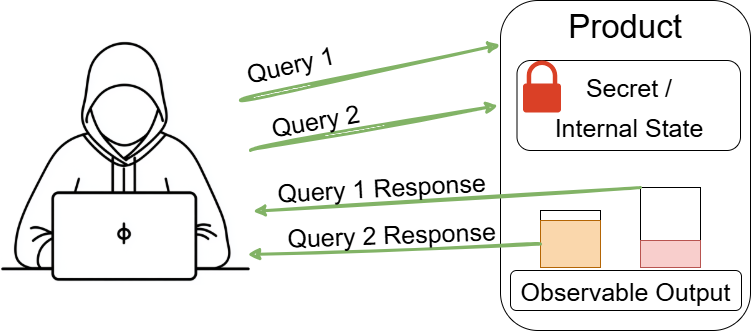
The product behaves differently or sends different responses under different circumstances in a way that is observable to an unauthorized actor.
Alternate Terms
Side Channel Attack
Observable Discrepancies are at the root of side channel attacks.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
An attacker can gain access to sensitive information about the system, including authentication information that may allow an attacker to gain access to the system. Other security-relevant information about the operation or internal state of the product may be revealed to an unauthorized actor, such as whether a particular operation was successful or not.
Read Application Data
Scope: Confidentiality
In some cases, discrepancies can be used by attackers to form a side channel. When cryptographic primitives are vulnerable to side-channel attacks, this could be used to reveal unencrypted plaintext in the worst case.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Strategy: Separation of Privilege
Compartmentalize the system to have "safe" areas where trust boundaries can be unambiguously drawn. Do not allow sensitive data to go outside of the trust boundary and always be careful when interfacing with a compartment outside of the safe area.
Ensure that appropriate compartmentalization is built into the system design, and the compartmentalization allows for and reinforces privilege separation functionality. Architects and designers should rely on the principle of least privilege to decide the appropriate time to use privileges and the time to drop privileges.
Implementation
Ensure that error messages only contain minimal details that are useful to the intended audience and no one else. The messages need to strike the balance between being too cryptic (which can confuse users) or being too detailed (which may reveal more than intended). The messages should not reveal the methods that were used to determine the error. Attackers can use detailed information to refine or optimize their original attack, thereby increasing their chances of success.
If errors must be captured in some detail, record them in log messages, but consider what could occur if the log messages can be viewed by attackers. Highly sensitive information such as passwords should never be saved to log files.
Avoid inconsistent messaging that might accidentally tip off an attacker about internal state, such as whether a user account exists or not.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Exposure of Sensitive Information to an Unauthorized Actor
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Non-Transparent Sharing of Microarchitectural Resources
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Discrepancies may be observable based on timing, control flow, communications (such as replies or requests), or general behavior.
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Architecture and Design
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
Class: Not Language-Specific
(Undetermined Prevalence)
Technologies
Class: Not Technology-Specific
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following code checks validity of the supplied username and password and notifies the user of a successful or failed login.
(bad code)
Example Language: Perl
my $username=param('username');
my $password=param('password');
if (IsValidUsername($username) == 1)
{
if (IsValidPassword($username, $password) == 1)
{
print "Login Successful";
}
else
{
print "Login Failed - incorrect password";
}
}
else
{
print "Login Failed - unknown username";
}
In the above code, there are different messages for when an incorrect username is supplied, versus when the username is correct but the password is wrong. This difference enables a potential attacker to understand the state of the login function, and could allow an attacker to discover a valid username by trying different values until the incorrect password message is returned. In essence, this makes it easier for an attacker to obtain half of the necessary authentication credentials.
While this type of information may be helpful to a user, it is also useful to a potential attacker. In the above example, the message for both failed cases should be the same, such as:
(result)
"Login Failed - incorrect username or password"
Example 2
In this example, the attacker observes how long an authentication takes when the user types in the correct password.
When the attacker tries their own values, they can first try strings of various length. When they find a string of the right length, the computation will take a bit longer, because the for loop will run at least once. Additionally, with this code, the attacker can possibly learn one character of the password at a time, because when they guess the first character right, the computation will take longer than a wrong guesses. Such an attack can break even the most sophisticated password with a few hundred guesses.
(bad code)
Example Language: Python
def validate_password(actual_pw, typed_pw):
if len(actual_pw) <> len(typed_pw):
return 0
for i in len(actual_pw):
if actual_pw[i] <> typed_pw[i]:
return 0
return 1
Note that in this example, the actual password must be handled in constant time as far as the attacker is concerned, even if the actual password is of an unusual length. This is one reason why it is good to use an algorithm that, among other things, stores a seeded cryptographic one-way hash of the password, then compare the hashes, which will always be of the same length.
Example 3
Non-uniform processing time causes timing channel.
(bad code)
Example Language: Other
Suppose an algorithm for implementing an encryption routine works fine per se, but the time taken to output the result of the encryption routine depends on a relationship between the input plaintext and the key (e.g., suppose, if the plaintext is similar to the key, it would run very fast).
In the example above, an attacker may vary the inputs, then observe differences between processing times (since different plaintexts take different time). This could be used to infer information about the key.
(good code)
Example Language: Other
Artificial delays may be added to ensure that all calculations take equal time to execute.
Example 4
Suppose memory access patterns for an encryption routine are dependent on the secret key.
An attacker can recover the key by knowing if specific memory locations have been accessed or not. The value stored at those memory locations is irrelevant. The encryption routine's memory accesses will affect the state of the processor cache. If cache resources are shared across contexts, after the encryption routine completes, an attacker in different execution context can discover which memory locations the routine accessed by measuring the time it takes for their own memory accesses to complete.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Crypto hardware wallet's power consumption relates to total number of pixels illuminated, creating a side channel in the USB connection that allows attackers to determine secrets displayed such as PIN numbers and passwords
Bulletin Board displays different error messages when a user exists or not, which makes it easier for remote attackers to identify valid users and conduct a brute force password guessing attack.
Operating System, when direct remote login is disabled, displays a different message if the password is correct, which allows remote attackers to guess the password via brute force methods.
Product sets a different TTL when a port is being filtered than when it is not being filtered, which allows remote attackers to identify filtered ports by comparing TTLs.
Version control system allows remote attackers to determine the existence of arbitrary files and directories via the -X command for an alternate history file, which causes different error messages to be returned.
FTP server generates an error message if the user name does not exist instead of prompting for a password, which allows remote attackers to determine valid usernames.
SSL implementation does not perform a MAC computation if an incorrect block cipher padding is used, which causes an information leak (timing discrepancy) that may make it easier to launch cryptographic attacks that rely on distinguishing between padding and MAC verification errors, possibly leading to extraction of the original plaintext, aka the "Vaudenay timing attack."
Virtual machine allows malicious web site operators to determine the existence of files on the client by measuring delays in the execution of the getSystemResource method.
Product uses a shorter timeout for a non-existent user than a valid user, which makes it easier for remote attackers to guess usernames and conduct brute force password guessing.
FTP server responds in a different amount of time when a given username exists, which allows remote attackers to identify valid usernames by timing the server response.
Browser allows remote attackers to determine the existence of arbitrary files by setting the src property to the target filename and using Javascript to determine if the web page immediately stops loading, which indicates whether the file exists or not.
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
OWASP Top Ten 2004 Category A7 - Improper Error Handling
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Comprehensive Categorization: Sensitive Information Exposure
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.

 Description
Description
 This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.