Vulnerability Mapping:ALLOWEDThis CWE ID could be used to map to real-world vulnerabilities in limited situations requiring careful review
(with careful review of mapping notes)
Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
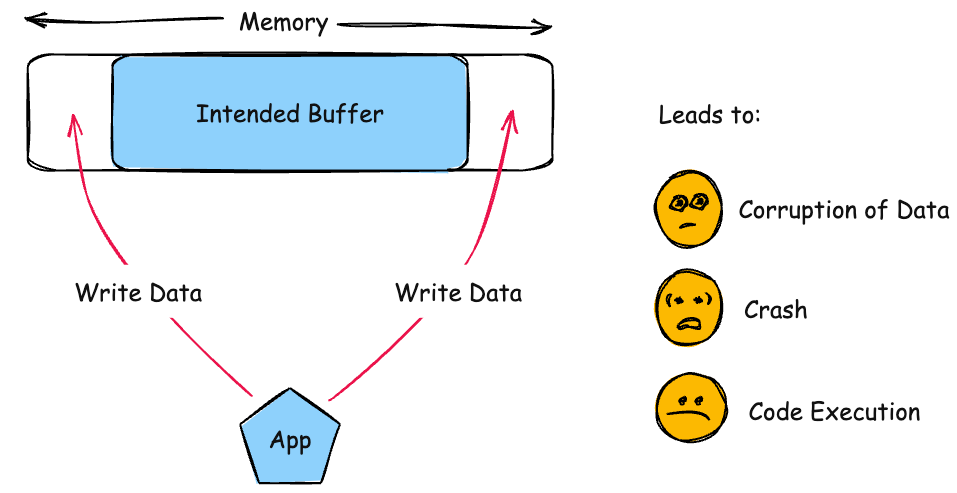
The product writes data past the end, or before the beginning, of the intended buffer.
Alternate Terms
Memory Corruption
Often used to describe the consequences of writing to memory outside the bounds of a buffer, or to memory that is otherwise invalid.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity
Write operations could cause memory corruption. In some cases, an adversary can modify control data such as return addresses in order to execute unexpected code.
DoS: Crash, Exit, or Restart
Scope: Availability
Attempting to access out-of-range, invalid, or unauthorized memory could cause the product to crash.
Unexpected State
Scope: Other
Subsequent write operations can produce undefined or unexpected results.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Strategy: Language Selection
Use a language that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
For example, many languages that perform their own memory management, such as Java and Perl, are not subject to buffer overflows. Other languages, such as Ada and C#, typically provide overflow protection, but the protection can be disabled by the programmer.
Be wary that a language's interface to native code may still be subject to overflows, even if the language itself is theoretically safe.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
Examples include the Safe C String Library (SafeStr) by Messier and Viega [REF-57], and the Strsafe.h library from Microsoft [REF-56]. These libraries provide safer versions of overflow-prone string-handling functions.
Note: This is not a complete solution, since many buffer overflows are not related to strings.
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Implementation
Consider adhering to the following rules when allocating and managing an application's memory:
Double check that the buffer is as large as specified.
When using functions that accept a number of bytes to copy, such as strncpy(), be aware that if the destination buffer size is equal to the source buffer size, it may not NULL-terminate the string.
Check buffer boundaries if accessing the buffer in a loop and make sure there is no danger of writing past the allocated space.
If necessary, truncate all input strings to a reasonable length before passing them to the copy and concatenation functions.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333].
Operation
Strategy: Environment Hardening
Use a CPU and operating system that offers Data Execution Protection (using hardware NX or XD bits) or the equivalent techniques that simulate this feature in software, such as PaX [REF-60] [REF-61]. These techniques ensure that any instruction executed is exclusively at a memory address that is part of the code segment.
For more information on these techniques see D3-PSEP (Process Segment Execution Prevention) from D3FEND [REF-1336].
Effectiveness: Defense in Depth
Note: This is not a complete solution, since buffer overflows could be used to overwrite nearby variables to modify the software's state in dangerous ways. In addition, it cannot be used in cases in which self-modifying code is required. Finally, an attack could still cause a denial of service, since the typical response is to exit the application.
Implementation
Replace unbounded copy functions with analogous functions that support length arguments, such as strcpy with strncpy. Create these if they are not available.
Effectiveness: Moderate
Note: This approach is still susceptible to calculation errors, including issues such as off-by-one errors (CWE-193) and incorrectly calculating buffer lengths (CWE-131).
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
Class: Memory-Unsafe
(Often Prevalent)
C
(Often Prevalent)
C++
(Often Prevalent)
Class: Assembly
(Undetermined Prevalence)
Technologies
Class: ICS/OT
(Often Prevalent)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following code attempts to save four different identification numbers into an array.
If returnChunkSize() happens to encounter an error it will return -1. Notice that the return value is not checked before the memcpy operation (CWE-252), so -1 can be passed as the size argument to memcpy() (CWE-805). Because memcpy() assumes that the value is unsigned, it will be interpreted as MAXINT-1 (CWE-195), and therefore will copy far more memory than is likely available to the destination buffer (CWE-787, CWE-788).
Example 3
This code takes an IP address from the user and verifies that it is well formed. It then looks up the hostname and copies it into a buffer.
This function allocates a buffer of 64 bytes to store the hostname. However, there is no guarantee that the hostname will not be larger than 64 bytes. If an attacker specifies an address which resolves to a very large hostname, then the function may overwrite sensitive data or even relinquish control flow to the attacker.
Note that this example also contains an unchecked return value (CWE-252) that can lead to a NULL pointer dereference (CWE-476).
Example 4
This code applies an encoding procedure to an input string and stores it into a buffer.
(bad code)
Example Language: C
char * copy_input(char *user_supplied_string){
int i, dst_index; char *dst_buf = (char*)malloc(4*sizeof(char) * MAX_SIZE); if ( MAX_SIZE <= strlen(user_supplied_string) ){
die("user string too long, die evil hacker!");
} dst_index = 0; for ( i = 0; i < strlen(user_supplied_string); i++ ){
The programmer attempts to encode the ampersand character in the user-controlled string. However, the length of the string is validated before the encoding procedure is applied. Furthermore, the programmer assumes encoding expansion will only expand a given character by a factor of 4, while the encoding of the ampersand expands by 5. As a result, when the encoding procedure expands the string it is possible to overflow the destination buffer if the attacker provides a string of many ampersands.
Example 5
In the following C/C++ code, a utility function is used to trim trailing whitespace from a character string. The function copies the input string to a local character string and uses a while statement to remove the trailing whitespace by moving backward through the string and overwriting whitespace with a NUL character.
(bad code)
Example Language: C
char* trimTrailingWhitespace(char *strMessage, int length) {
However, this function can cause a buffer underwrite if the input character string contains all whitespace. On some systems the while statement will move backwards past the beginning of a character string and will call the isspace() function on an address outside of the bounds of the local buffer.
Example 6
The following code allocates memory for a maximum number of widgets. It then gets a user-specified number of widgets, making sure that the user does not request too many. It then initializes the elements of the array using InitializeWidget(). Because the number of widgets can vary for each request, the code inserts a NULL pointer to signify the location of the last widget.
(bad code)
Example Language: C
int i; unsigned int numWidgets; Widget **WidgetList;
However, this code contains an off-by-one calculation error (CWE-193). It allocates exactly enough space to contain the specified number of widgets, but it does not include the space for the NULL pointer. As a result, the allocated buffer is smaller than it is supposed to be (CWE-131). So if the user ever requests MAX_NUM_WIDGETS, there is an out-of-bounds write (CWE-787) when the NULL is assigned. Depending on the environment and compilation settings, this could cause memory corruption.
Example 7
The following is an example of code that may result in a buffer underwrite. This code is attempting to replace the substring "Replace Me" in destBuf with the string stored in srcBuf. It does so by using the function strstr(), which returns a pointer to the found substring in destBuf. Using pointer arithmetic, the starting index of the substring is found.
(bad code)
Example Language: C
int main() {
...
char *result = strstr(destBuf, "Replace Me");
int idx = result - destBuf;
strcpy(&destBuf[idx], srcBuf);
...
}
In the case where the substring is not found in destBuf, strstr() will return NULL, causing the pointer arithmetic to be undefined, potentially setting the value of idx to a negative number. If idx is negative, this will result in a buffer underwrite of destBuf.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Font rendering library does not properly
handle assigning a signed short value to an unsigned
long (CWE-195), leading to an integer wraparound
(CWE-190), causing too small of a buffer (CWE-131),
leading to an out-of-bounds write
(CWE-787).
The reference implementation code for a Trusted Platform Module does not implement length checks on data, allowing for an attacker to write 2 bytes past the end of a buffer.
Chain: integer truncation (CWE-197) causes small buffer allocation (CWE-131) leading to out-of-bounds write (CWE-787) in kernel pool, as exploited in the wild per CISA KEV.
chain: mobile phone Bluetooth implementation does not include offset when calculating packet length (CWE-682), leading to out-of-bounds write (CWE-787)
Heap-based buffer overflow in media player using a long entry in a playlist
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
At the point when the product writes data to an invalid location, it is likely that a separate weakness already occurred earlier. For example, the product might alter an index, perform incorrect pointer arithmetic, initialize or release memory incorrectly, etc., thus referencing a memory location outside the buffer.
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Automated static analysis generally does not account for environmental considerations when reporting out-of-bounds memory operations. This can make it difficult for users to determine which warnings should be investigated first. For example, an analysis tool might report buffer overflows that originate from command line arguments in a program that is not expected to run with setuid or other special privileges.
Effectiveness: High
Note:Detection techniques for buffer-related errors are more mature than for most other weakness types.
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the software using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The software's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Automated Dynamic Analysis
Use tools that are integrated during
compilation to insert runtime error-checking mechanisms
related to memory safety errors, such as AddressSanitizer
(ASan) for C/C++ [REF-1518].
Effectiveness: Moderate
Note:Crafted inputs are necessary to
reach the code containing the error, such as generated
by fuzzers. Also, these tools may reduce performance,
and they only report the error condition - not the
original mistake that led to the
error.
Functional Areas
Memory Management
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2019 CWE Top 25 Most Dangerous Software Errors
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2021 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2023 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2024 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2025 CWE Top 25 Most Dangerous Software Weaknesses
Vulnerability Mapping Notes
Usage
ALLOWED-WITH-REVIEW
(this CWE ID could be used to map to real-world vulnerabilities in limited situations requiring careful review)
Reasons
Frequent Misuse,
Abstraction
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities. However, closer examination is required.
Comments
While this CWE is allowed for mapping, it has more specific children that might be a better fit. Carefully read both the name and description to ensure that this mapping is appropriate. Consider the root cause errors that have led to the out-of-bounds write by examining "CanFollow" relationships for this entry.
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 5: Buffer Overruns." Page 89. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 3, "Nonexecutable Stack", Page 76. 1st Edition. Addison Wesley. 2006.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 5, "Protection Mechanisms", Page 189. 1st Edition. Addison Wesley. 2006.

 Description
Description
 This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.